 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMultiAgents: A Multi-Agent Framework for Video Question Answering
Apr 30, 2025Video Question Answering (VQA) inherently relies on multimodal reasoning, integrating visual, temporal, and linguistic cues to achieve a deeper understanding of video content. However, many existing methods rely on feeding frame-level captions into a single model, making it difficult to adequately capture temporal and interactive contexts. To address this limitation, we introduce VideoMultiAgents, a framework that integrates specialized agents for vision, scene graph analysis, and text processing. It enhances video understanding leveraging complementary multimodal reasoning from independently operating agents. Our approach is also supplemented with a question-guided caption generation, which produces captions that highlight objects, actions, and temporal transitions directly relevant to a given query, thus improving the answer accuracy. Experimental results demonstrate that our method achieves state-of-the-art performance on Intent-QA (79.0%, +6.2% over previous SOTA), EgoSchema subset (75.4%, +3.4%), and NExT-QA (79.6%, +0.4%). The source code is available at https://github.com/PanasonicConnect/VideoMultiAgents.
Panoramic Distortion-Aware Tokenization for Person Detection and Localization Using Transformers in Overhead Fisheye Images
Mar 18, 2025Person detection methods are used widely in applications including visual surveillance, pedestrian detection, and robotics. However, accurate detection of persons from overhead fisheye images remains an open challenge because of factors including person rotation and small-sized persons. To address the person rotation problem, we convert the fisheye images into panoramic images. For smaller people, we focused on the geometry of the panoramas. Conventional detection methods tend to focus on larger people because these larger people yield large significant areas for feature maps. In equirectangular panoramic images, we find that a person's height decreases linearly near the top of the images. Using this finding, we leverage the significance values and aggregate tokens that are sorted based on these values to balance the significant areas. In this leveraging process, we introduce panoramic distortion-aware tokenization. This tokenization procedure divides a panoramic image using self-similarity figures that enable determination of optimal divisions without gaps, and we leverage the maximum significant values in each tile of token groups to preserve the significant areas of smaller people. To achieve higher detection accuracy, we propose a person detection and localization method that combines panoramic-image remapping and the tokenization procedure. Extensive experiments demonstrated that our method outperforms conventional methods when applied to large-scale datasets.
hear-your-action: human action recognition by ultrasound active sensing
Sep 15, 2023



Action recognition is a key technology for many industrial applications. Methods using visual information such as images are very popular. However, privacy issues prevent widespread usage due to the inclusion of private information, such as visible faces and scene backgrounds, which are not necessary for recognizing user action. In this paper, we propose a privacy-preserving action recognition by ultrasound active sensing. As action recognition from ultrasound active sensing in a non-invasive manner is not well investigated, we create a new dataset for action recognition and conduct a comparison of features for classification. We calculated feature values by focusing on the temporal variation of the amplitude of ultrasound reflected waves and performed classification using a support vector machine and VGG for eight fundamental action classes. We confirmed that our method achieved an accuracy of 97.9% when trained and evaluated on the same person and in the same environment. Additionally, our method achieved an accuracy of 89.5% even when trained and evaluated on different people. We also report the analyses of accuracies in various conditions and limitations.
PALF: Pre-Annotation and Camera-LiDAR Late Fusion for the Easy Annotation of Point Clouds
Apr 13, 20233D object detection has become indispensable in the field of autonomous driving. To date, gratifying breakthroughs have been recorded in 3D object detection research, attributed to deep learning. However, deep learning algorithms are data-driven and require large amounts of annotated point cloud data for training and evaluation. Unlike 2D image labels, annotating point cloud data is difficult due to the limitations of sparsity, irregularity, and low resolution, which requires more manual work, and the annotation efficiency is much lower than 2D image.Therefore, we propose an annotation algorithm for point cloud data, which is pre-annotation and camera-LiDAR late fusion algorithm to easily and accurately annotate. The contributions of this study are as follows. We propose (1) a pre-annotation algorithm that employs 3D object detection and auto fitting for the easy annotation of point clouds, (2) a camera-LiDAR late fusion algorithm using 2D and 3D results for easily error checking, which helps annotators easily identify missing objects, and (3) a point cloud annotation evaluation pipeline to evaluate our experiments. The experimental results show that the proposed algorithm improves the annotating speed by 6.5 times and the annotation quality in terms of the 3D Intersection over Union and precision by 8.2 points and 5.6 points, respectively; additionally, the miss rate is reduced by 31.9 points.
Deep Single Image Camera Calibration by Heatmap Regression to Recover Fisheye Images Under ManhattanWorld AssumptionWithout Ambiguity
Mar 30, 2023



In orthogonal world coordinates, a Manhattan world lying along cuboid buildings is widely useful for various computer vision tasks. However, the Manhattan world has much room for improvement because the origin of pan angles from an image is arbitrary, that is, four-fold rotational symmetric ambiguity of pan angles. To address this problem, we propose a definition for the pan-angle origin based on the directions of the roads with respect to a camera and the direction of travel. We propose a learning-based calibration method that uses heatmap regression to remove the ambiguity by each direction of labeled image coordinates, similar to pose estimation keypoints. Simultaneously, our two-branched network recovers the rotation and removes fisheye distortion from a general scene image. To alleviate the lack of vanishing points in images, we introduce auxiliary diagonal points that have the optimal 3D arrangement of spatial uniformity. Extensive experiments demonstrated that our method outperforms conventional methods on large-scale datasets and with off-the-shelf cameras.
Masking and Mixing Adversarial Training
Feb 16, 2023



While convolutional neural networks (CNNs) have achieved excellent performances in various computer vision tasks, they often misclassify with malicious samples, a.k.a. adversarial examples. Adversarial training is a popular and straightforward technique to defend against the threat of adversarial examples. Unfortunately, CNNs must sacrifice the accuracy of standard samples to improve robustness against adversarial examples when adversarial training is used. In this work, we propose Masking and Mixing Adversarial Training (M2AT) to mitigate the trade-off between accuracy and robustness. We focus on creating diverse adversarial examples during training. Specifically, our approach consists of two processes: 1) masking a perturbation with a binary mask and 2) mixing two partially perturbed images. Experimental results on CIFAR-10 dataset demonstrate that our method achieves better robustness against several adversarial attacks than previous methods.
Data Augmentation by Selecting Mixed Classes Considering Distance Between Classes
Sep 12, 2022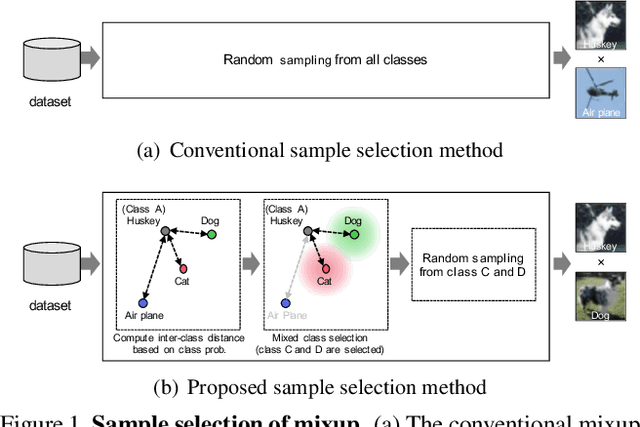
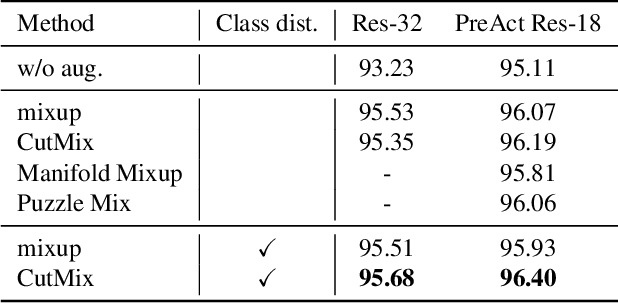
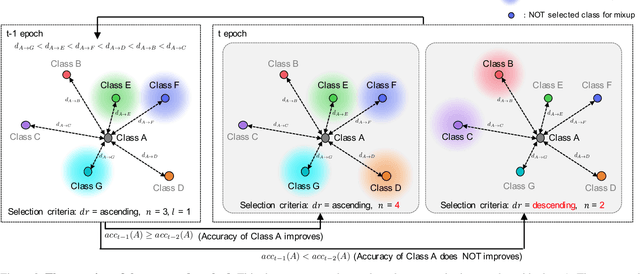
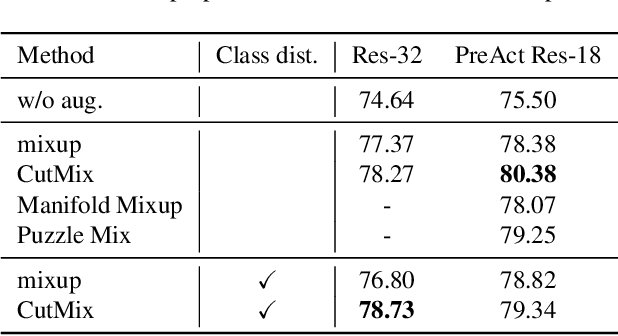
Data augmentation is an essential technique for improving recognition accuracy in object recognition using deep learning. Methods that generate mixed data from multiple data sets, such as mixup, can acquire new diversity that is not included in the training data, and thus contribute significantly to accuracy improvement. However, since the data selected for mixing are randomly sampled throughout the training process, there are cases where appropriate classes or data are not selected. In this study, we propose a data augmentation method that calculates the distance between classes based on class probabilities and can select data from suitable classes to be mixed in the training process. Mixture data is dynamically adjusted according to the training trend of each class to facilitate training. The proposed method is applied in combination with conventional methods for generating mixed data. Evaluation experiments show that the proposed method improves recognition performance on general and long-tailed image recognition datasets.
Few-shot Adaptive Object Detection with Cross-Domain CutMix
Aug 31, 2022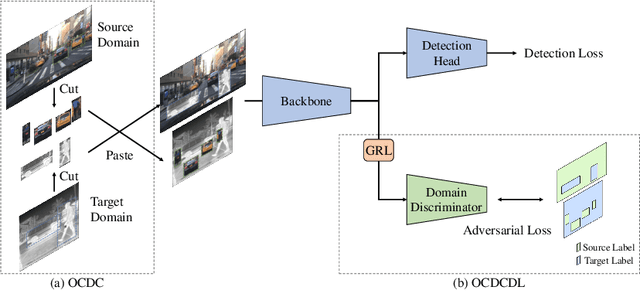
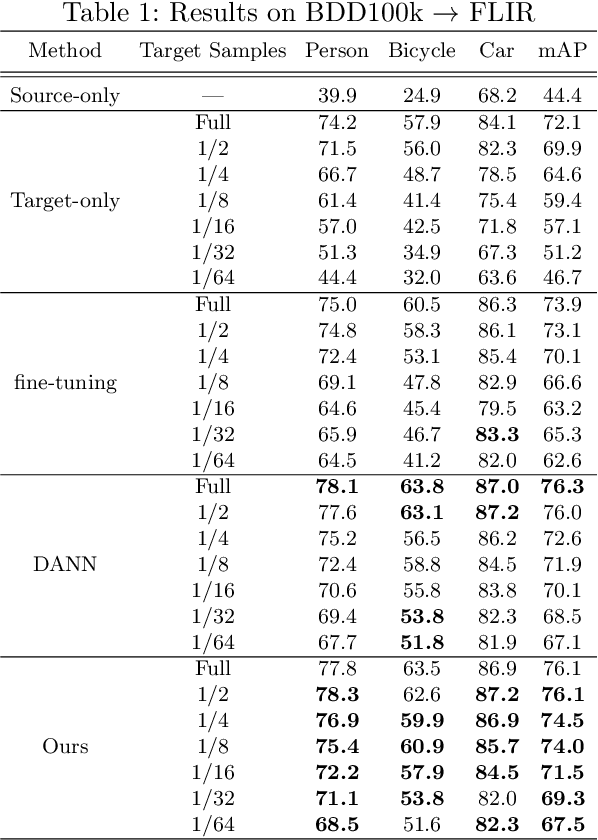
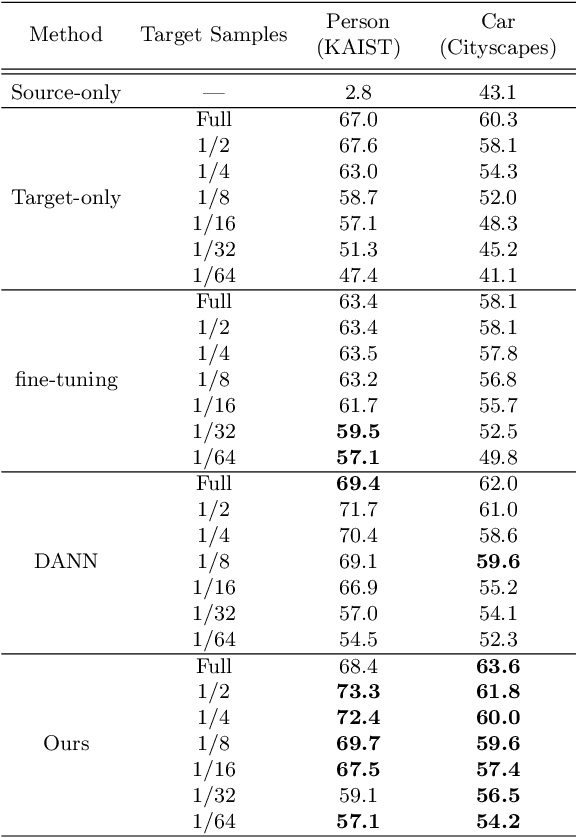
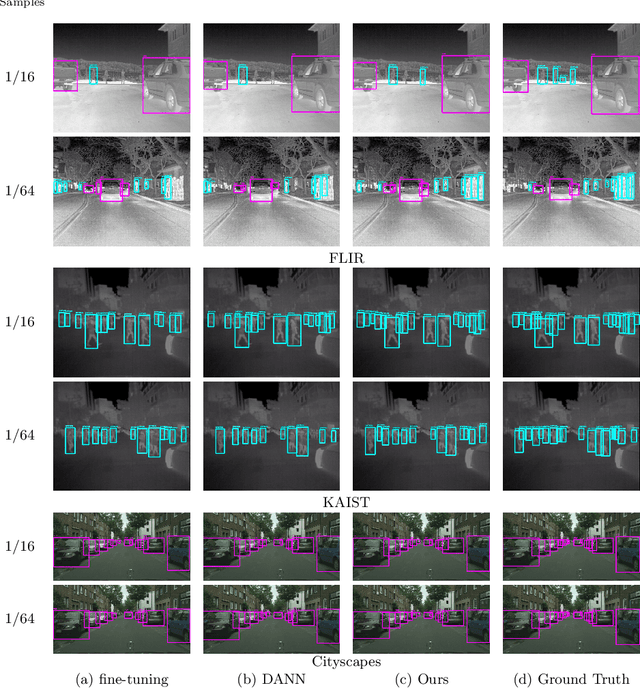
In object detection, data amount and cost are a trade-off, and collecting a large amount of data in a specific domain is labor intensive. Therefore, existing large-scale datasets are used for pre-training. However, conventional transfer learning and domain adaptation cannot bridge the domain gap when the target domain differs significantly from the source domain. We propose a data synthesis method that can solve the large domain gap problem. In this method, a part of the target image is pasted onto the source image, and the position of the pasted region is aligned by utilizing the information of the object bounding box. In addition, we introduce adversarial learning to discriminate whether the original or the pasted regions. The proposed method trains on a large number of source images and a few target domain images. The proposed method achieves higher accuracy than conventional methods in a very different domain problem setting, where RGB images are the source domain, and thermal infrared images are the target domain. Similarly, the proposed method achieves higher accuracy in the cases of simulation images to real images.
Invisible-to-Visible: Privacy-Aware Human Segmentation using Airborne Ultrasound via Collaborative Learning Probabilistic U-Net
May 11, 2022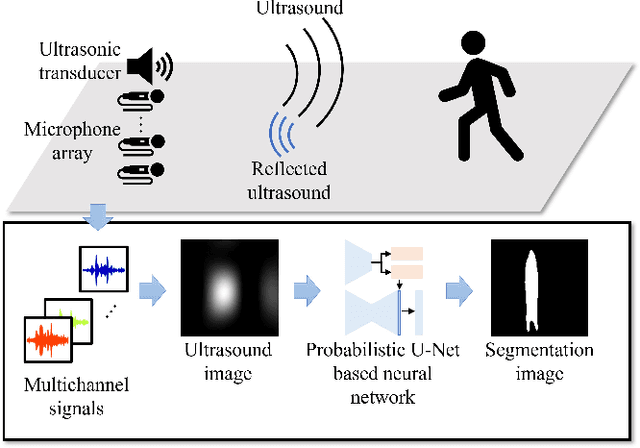

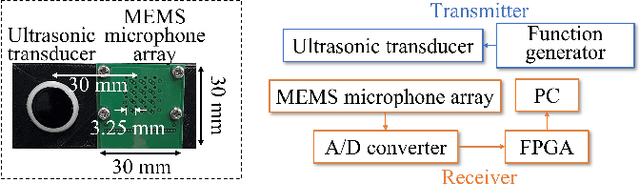
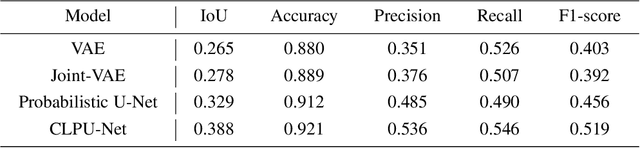
Color images are easy to understand visually and can acquire a great deal of information, such as color and texture. They are highly and widely used in tasks such as segmentation. On the other hand, in indoor person segmentation, it is necessary to collect person data considering privacy. We propose a new task for human segmentation from invisible information, especially airborne ultrasound. We first convert ultrasound waves to reflected ultrasound directional images (ultrasound images) to perform segmentation from invisible information. Although ultrasound images can roughly identify a person's location, the detailed shape is ambiguous. To address this problem, we propose a collaborative learning probabilistic U-Net that uses ultrasound and segmentation images simultaneously during training, closing the probabilistic distributions between ultrasound and segmentation images by comparing the parameters of the latent spaces. In inference, only ultrasound images can be used to obtain segmentation results. As a result of performance verification, the proposed method could estimate human segmentations more accurately than conventional probabilistic U-Net and other variational autoencoder models.
Invisible-to-Visible: Privacy-Aware Human Instance Segmentation using Airborne Ultrasound via Collaborative Learning Variational Autoencoder
Apr 15, 2022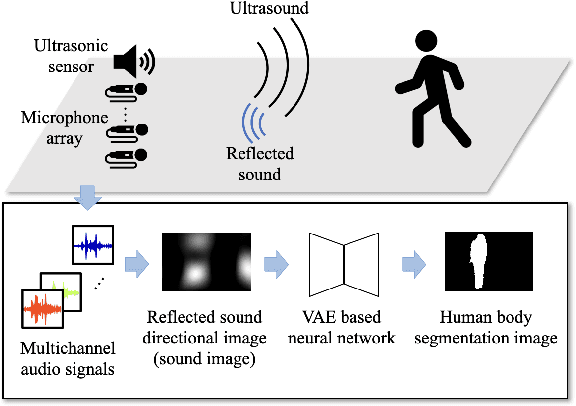
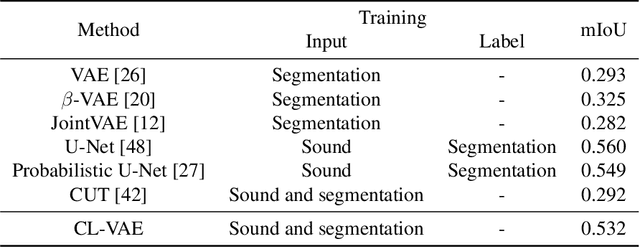
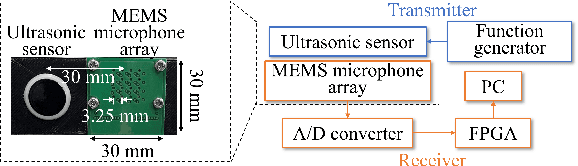

In action understanding in indoor, we have to recognize human pose and action considering privacy. Although camera images can be used for highly accurate human action recognition, camera images do not preserve privacy. Therefore, we propose a new task for human instance segmentation from invisible information, especially airborne ultrasound, for action recognition. To perform instance segmentation from invisible information, we first convert sound waves to reflected sound directional images (sound images). Although the sound images can roughly identify the location of a person, the detailed shape is ambiguous. To address this problem, we propose a collaborative learning variational autoencoder (CL-VAE) that simultaneously uses sound and RGB images during training. In inference, it is possible to obtain instance segmentation results only from sound images. As a result of performance verification, CL-VAE could estimate human instance segmentations more accurately than conventional variational autoencoder and some other models. Since this method can obtain human segmentations individually, it could be applied to human action recognition tasks with privacy protection.